In diesem umfassenden Tutorial geht es um den Einstieg in Python für Machine Learning. Dabei werden zunächst die Vorteile von Python für AI Anwendungen erklärt. Außerdem wird eine leicht verständliche und intuitive Erklärung von Machine Learning (ML) gegeben. Das Konzept soll dann mit Scikit-learn an einem praktischen Code-Beispiel verdeutlicht werden. Davor geht es um wichtige Voraussetzungen eines gelungenen Starts in Python für Machine Learning.
Inhalte
Warum Python für AI?
Es gibt zahlreiche Gründe für Python als erste Wahl bei AI bzw. Machine Learning.
Python ist Industriestandard für Machine Learning Anwendungen. Bedeutende ML Frameworks wie Tensorflow (von Google), PyTorch (von Facebook) und das in dieser Anleitung verwendete Scikit-learn sind in Python geschrieben.
Außerdem steht die Python Software unter einer freizügigen Open-Source-Lizenz. Das bedeutet jeder kann Python kostenlos (auch für gewerbliche Zwecke) in seinen Anwendungen benutzen.
Der Kern von Python bietet bereits viele Funktionen. Dazu gibt es eine Vielzahl weiterer Software-Packages in Python, welche ebenfalls Open-Source sind und ML Anwendungen erheblich vereinfachen oder sogar erst möglich machen. Dazu zählen beispielsweise Scikit-learn (ML Toolkit), Numpy (Datenmanipulation), Pandas (Datenmanipulation & -analyse) und Matplotlib (Visualisierung).
Python ist eine universelle Programmiersprache und einfach zu erlernen. Die Sprache lässt sich nicht nur für Data Science/ML sondern auch für Web Development, zur Systemadministration und vieles weiteres einsetzen. Außerdem werden verschiedene Programmierstile (z. B. objektorientiert, funktional) unterstützt. Python erfreut sich großer Beliebtheit und wird von einer aktiven Community stetig weiterentwickelt. Es lohnt sich Python zu lernen!
Was ist Machine Learning?
Machine Learning (oder Maschinelles Lernen) ist eine Teildisziplin der Künstlichen Intelligenz (KI) bzw. Artificial Intelligence (AI). Beide Begriffe werden oft synonym verwendet.
Es gibt viele Definitionen von Machine Learning. Eine bedeutende lautet:
“Machine Learning is the field of study that gives computers the ability
to learn without being explicitly programmed.” – Arthur Samuel, 1959
Wie kann ein Computer in der Lage sein zu lernen, ohne explizit dafür programmiert zu werden? Die Antwort lautet: Mit den richtigen Daten und lernenden Algorithmen. Damit lassen sich bestimmte Probleme tatsächlich sehr gut lösen. Machine Learning begegnet uns im Alltag bereits seit einigen Jahren in vielen Bereichen: Videos schauen, Musik hören, Spam-Filter, Online-Shopping, Online-Partnersuche ..
Machine Learning ist immer auch Data Science. Es geht um die automatische Extraktion von Wissen aus Daten.
Die Extraktion gelingt, indem spezielle lernende Algorithmen auf die Daten “losgelassen” werden und als Ergebnis (hoffentlich) brauchbare Modelle zur Problemlösung erzeugen. Die Algorithmen werden in überwachte (supervised) und nicht überwachte (unsupervised) Verfahren eingeteilt.
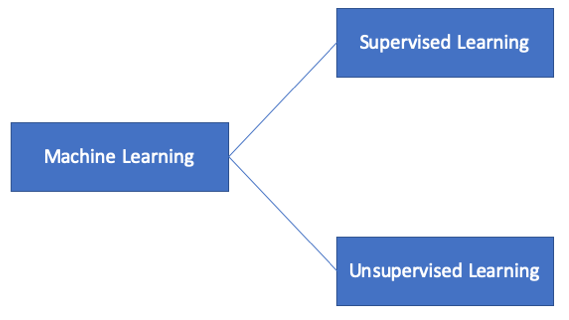
Beim Supervised Learning kennt der Algorithmus die richtige Lösung, weil sie im Datensatz vorhanden ist. Beispiele für solche Verfahren sind Entscheidungsbäume (Decision Trees), Regressionsanalysen, Support Vector Machines (SVM) und Künstliche Neuronale Netze (Artificial Neural Networks).
Dagegen muss die Lösung beim Unsupervised Learning vom Algorithmus selbst gefunden werden und ist nicht explizit im Datensatz ausgewiesen. Beispiele hierfür sind Clustering-Methoden und der Apriori-Algorithmus.
In diesem Beitrag beschränken wir uns auf Supervised Learning.
Beispiel:
Die Funktionsweise von Machine Learning lässt sich sehr gut anhand einer Linearen Regressionsanalyse erklären.
Bei diesem statistischen Verfahren wird versucht eine abhängige Variable mithilfe einer oder mehrerer unabhängiger Variable(n) vorherzusagen. Dabei wird ein linearer Zusammenhang zwischen beiden Variablen angenommen.
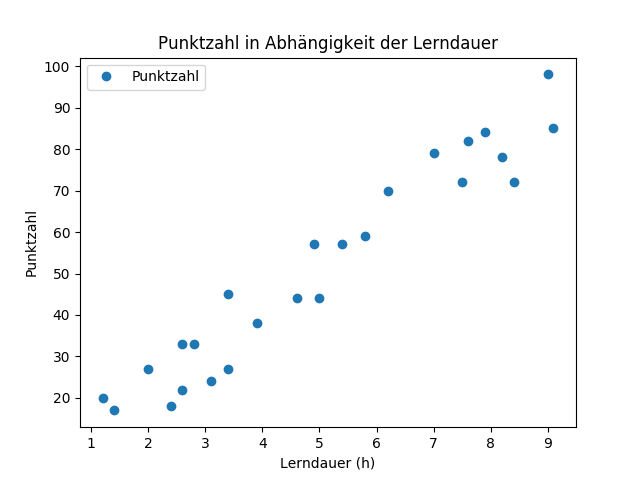
Wir wollen das Abschneiden von Studenten bei einer Prüfung in Abhängigkeit der Lerndauer mithilfe einer Regressionsanalyse vorhersagen. Dafür liegen uns Daten vor. Für 25 Studenten haben wir die Lerndauer (h) und das Abschneiden bei einem Test (erreichte Punktzahl von maximal 100 Punkten). Dabei ist die erreichte Punktzahl die abhängige Variable und die Lerndauer die unabhängige Variable.
Im Schaubild sind beide Variablen dargestellt. Auf der Y-Achse sieht man die erreichte Punktzahl. Auf der X-Achse steht die Lerndauer. Jeder Punkt im Schaubild steht für einen Fall (Student) in unserem Datensatz. Man erkennt leicht, dass die Daten einem linearen Trend folgen.
Wir fassen den Entschluss, dass eine einfache Linie den Trend in den Daten sehr gut erfasst. Also wenden wir mit der Linearen Regression einen Algorithmus an, der uns ein lineares Modell liefert. Die allgemeine Formel der linearen Funktion lautet:
y = mx + b
Mit dem Algorithmus erhalten wir bestimmte Werte für m und b, sodass unsere Daten durch die resultierende Linie bestmöglich beschrieben werden. Das Ergebnis einer linearen Regression (in Python mit Scikit-learn) lautet:
y = 9,38x + 4,82
Im nächsten Schaubild sehen wir die ermittelte Regressionsgerade. Diese Linie (unser Modell) beschreibt die erreichte Punktzahl für eine entsprechende Lerndauer. Wenn wir die Punktzahl eines (neuen) Studenten prognostizieren möchten, so müssen wir einfach seine Lerndauer (x-Wert) in die Formel eintragen.
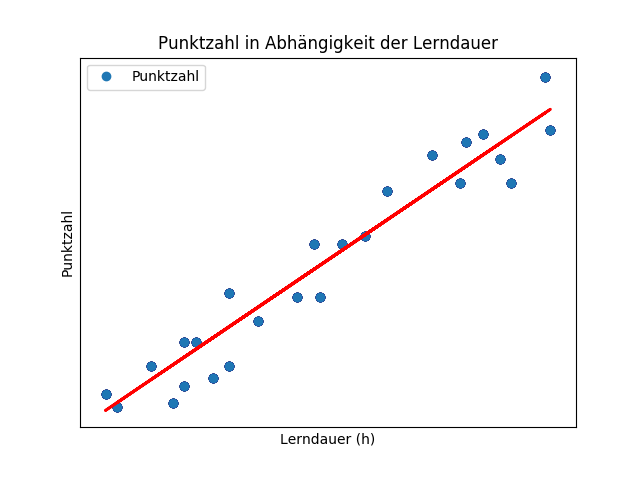
Unser einfaches Modell beschreibt die Daten ausreichend gut aber es gibt merkliche Abweichungen zwischen prognostizierten und tatsächlichen Werten. Damit sollte aber auch nur die allgemeine Funktionsweise von (supervised ) Machine Learning dargestellt werden.
Dabei haben wir ein einfaches Machine Learning Verfahren (Lineare Regression) auf wenig Daten (25 Fälle mit je 2 Features/Variablen) angewendet. Außerdem haben wir die Performance des Modells nur sehr rudimentär bewertet.
Im Folgenden Code-Beispiel in Python werden mehrere (komplexere) Machine Learning Verfahren auf einen anderen Datensatz angewendet. Dabei wird auch näher auf die Performance des Modells eingegangen. Zusätzlich werden wichtige Schritte bei Machine Learning verdeutlicht.
Voraussetzungen für Machine Learning mit Python
Es gibt ein paar Voraussetzungen, die erfüllt sein sollten, bevor man Machine Learning in Python erfolgreich anwenden kann. Zum einen sind das technische Voraussetzungen (Installationen). Zum anderen erfordert Machine Learning Fachkenntnisse in bestimmten Bereichen.
Erfahrungsgemäß sind die technischen Voraussetzungen (Installationen) schnell erfüllt.
Dagegen dauert es seine Zeit bis man die Grundlagen und Konzepte hinter Machine Learning verstanden hat. Natürlich kann man sich diese nach und nach aneignen. Es ist also nicht schlimm, wenn man in (Code-)Beispielen noch nicht alles en Detail versteht.
Tatsächlich war es noch nie so einfach mit Machine Learning anzufangen wie heute. Vor allem im Python-Ökosystem existieren zahlreiche ausgefeilte und kostenlose Werkzeuge, die einem die Arbeit enorm erleichtern! 🙂
Entwicklungsumgebung (Jupyter Notebook)
Zunächst mal benötigt man eine Entwicklungsumgebung, um Machine Learning Anwendungen in Python programmieren zu können.
Hinweis: Am besten ladet ihr euch nicht alle Komponenten der Entwicklungsumgebung einzeln herunter, sondern benutzt die Software Anaconda. Mit diesem (kostenlosen) Paket- und Umgebungsmanager für Python erhaltet ihr alle Werkzeuge (Python, Pip, Jupyter) für Machine Learning in Python.
Die Entwicklungsumgebung besteht aus Python (Version 3.7 oder höher). Python ist eine interpretierte Programmiersprache. Das bedeutet der geschriebene Python Programmcode wird von einem anderen Programm (dem Interpreter) ausgeführt. Es gibt den Standard Python-Interpreter (CPython) für alle gängigen Betriebssysteme (Windows, macOS, Linux).
Weiterhin benötigt man den Python-Paketmanager Pip. Damit lassen sich ganz einfach Python Pakete herunterladen und installieren. Diese Pakete enthalten wiederum Module. Es gibt für (fast) jede Aufgabe ein entsprechendes Python Modul. Mit Pip muss man also das Rad nicht immer neu erfinden, sondern kann sich einfach die passenden Pakete/Module besorgen!
Das letzte Tool im Machine Learning Werkzeugkasten ist Jupyter Notebook. Dabei handelt es sich um eine integrierte Entwicklungsumgebung für Data Science im Browser. Mit Jupyter kann man schnell und einfach Python Code im Browser schreiben und interaktiv ausführen. Außerdem lassen sich die Ergebnisse sehr leicht mit anderen teilen. Python Code wird in Jupyter Notebooks in Dateien mit der Endung .ipynb abgelegt. Diese können neben Python Code auch normalen Text, Bilder, Videos und Markup (Markdown, HTML) enthalten. Eine gute Einführung in Jupyter Notebook findet ihr hier.
Python Grundlagen
Machine Learning in Python erfordert grundlegende Kenntnisse in der Programmierung mit Python. Glücklicherweise gilt Python als einfach zu erlernen und zeichnet sich durch eine klare Syntax aus. Ich möchte hier nicht auf die Grundlagen der Programmierung in Python eingehen aber es gibt zahlreiche hervorragende und kostenlose Ressourcen zum Lernen von Python im Web:
Learn Python und W3Schools bieten gute Tutorials für Einsteiger.
Realpython ist eine hervorragende Ressource für Python und bietet verschiedene Tutorials für Einsteiger und Fortgeschrittene.
Außerdem finden sich eine ganze Reihe guter Tutorials auf YouTube.
Statistik und Mathematik für Machine Learning in Python
Machine Learning beinhaltet viel Statistik und Mathematik. Grundlegende Statistik und Mathematik Kenntnisse sind also von Vorteil für Machine Learning in Python.
Man braucht aber keinen Abschluss in Statistik oder Mathematik. Wichtige Themen wie Lineare Algebra und Analysis begegnen vielen bereits in der Schule (z. B. beim Mathe-Abi). Außerdem werden einige für Machine Learning relevante Statistik- und Mathematik-Inhalte in vielen Studiengängen (Wirtschaftswissenschaften & Ingenieurswissenschaften) vermittelt. Darauf lässt sich sehr gut aufbauen.
Mit der nötigen Motivation kann man sich die Konzepte aber bestimmt auch aneignen, wenn man bisher wenig mit Mathe und Statistik in Berührung gekommen ist!
Machine Learning Tutorial mit Scikit-learn, Pandas und Numpy
Daten
Für dieses Tutorial verwenden wir den Iris Datensatz (CSV Download) vom UCI Machine Learning Repository: Iris Data Set. Dieser kleine Datensatz ist häufig in der Literatur zu Data Science anzutreffen. Er besteht aus 150 Fällen (Zeilen) mit jeweils 5 Features (Spalten):
- Sepal length
- Sepal width
- Petal length
- Petal width
- Species
Jeder Fall repräsentiert eine Iris-Blume mit einer Sepal length, Sepal width, Petal length, Petal width und Species (Anm.: Denglisch lässt sich in einem ML Kontext nicht immer vermeiden). Dabei gibt es 3 Iris-Spezies (Iris Setosa, Iris Versicolor, Iris Virginica) im Datensatz. Jede Klasse kommt 50mal im Datensatz vor (gleiche Häufigkeit).
Wir möchten nun mithilfe von Machine Learning ein Klassifizierungsproblem lösen. Dabei stellt die Spezies die abhängige Variable dar und Sepal length, Sepal width, Petal length, Petal width sind unabhängige Variablen.
Am besten erstellt ihr euch einen eigenen Projektordner für dieses Tutorial mit allen relevanten Dateien. Außerdem solltet ihr im Projektordner einen weiteren Ordner namens “data” erstellen und darin die heruntergeladene CSV-Datei (Iris Daten) ablegen.
Installation von Scikit-learn, Pandas und Numpy
In diesem Abschnitt gehe ich davon aus, dass die vorher beschriebene Entwicklungsumgebung bereit ist.
Zunächst müssen wir die benötigten Packages Numpy, Pandas und Scikit-learn mit Pip herunterladen.
Optional: Standardmäßig werden alle installierten Packages/Module euer Standard-Python-Installation hinzugefügt. Es empfiehlt sich jedoch mit verschiedenen Umgebungen (Python-Installationen) für verschiedene Projekte zu arbeiten. Mit Conda könnt ihr ganz einfach neue Python-Umgebungen anlegen und aktivieren. Eine Anleitung dazu findet ihr hier.
Öffnet die Kommandozeile (Shell) und navigiert in den Projektordner.
Nützliche Kommandozeilen-Befehle:
- pwd: Zeigt das aktuelle Verzeichnis (Arbeitsverzeichnis) an.
- ls: Zeigt Inhalte des aktuellen Verzeichnisses.
- cd <name>: Navigiert in das <name> Verzeichnis.
- cd .. : Navigiert zurück in das höher gelegene Verzeichnis.
(Diese Befehle gelten für Linux/macOS. Bei Windows kann es zu Abweichungen kommen.)
Zur Installation von Numpy gebt ihr folgendes in die Kommandozeile ein:
$ pip install numpy
Numpy schafft mit der Datenstruktur “ndarray” (mehrdimensionales Array) eine wichtige Grundlage für Machine Learning in Python. Damit lassen sich Berechnungen für große Datenmengen effizient durchführen, weil die Werte in Numpy-Arrays alle den gleichen Datentyp besitzen. Mit normalen Python-Arrays (Listen) ist dies nicht möglich, da hier die Werte unterschiedliche Datentypen haben können.
Zur Installation von Pandas gebt ihr folgendes in die Kommandozeile ein:
$ pip install pandas
Pandas bietet wichtige Methoden zur Analyse und Manipulation von Daten in Python. Beispielsweise lassen sich damit CSV- und Excel-Dateien laden. Außerdem ermöglicht Pandas mit der “DataFrame” Datenstruktur eine zweidimensionale und tabellarische Repräsentation von Daten in Python.
Zur Installation von Scikit-learn gebt ihr folgendes in die Kommandozeile ein:
$ pip install scikit-learn
Scikit-learn ist ein umfangreiches Package für Machine Learning in Python. Darin sind zahlreiche Algorithmen effizient implementiert und es bietet Lösungen für viele Machine Learning spezifische Herausforderungen. Scikit-learn ist durch sein hervorragendes API-Design einfach, effizient und leicht zugänglich für Nicht-Experten.
Zur Installation von Matplotlib gebt ihr folgendes in die Kommandozeile ein:
$ pip install matplotlib
Matplotlib ist eine umfassende Bibliothek zur Visualisierung von Daten in Python.
Machine Learning Code im Jupyter Notebook
Damit das Jupyter Notebook startet müsst ihr folgendes in die Kommandozeile eingeben während ihr euch im Projektordner befindet:
$ jupyter notebook
In der Shell sollte nun der Jupyter Notebook Server gestartet sein und der Browser öffnet sich automatisch.
Nun klickt ihr auf “New” und erstellt ein neues Python 3 Notebook. Im neuen Notebook klickt ihr am besten doppelt auf den Namen “Untitled” und benennt es um – z. B. in “Machine_Learning_Tutorial”.
Danach fügt ihr diesen Inhalt in die erste Code-Zelle:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
Damit importieren wir die Module Numpy, Pandas und Matplotlib (bzw. Pyplot) aus den vorher mit Pip installierten Packages.
Außerdem geben wir jedem dieser Module ein Alias (“import .. as ..”). Die hier verwendeten Aliasse (np, pd und plt) sind quasi ein Standard in der Python Data Science Community.
Führt den Code aus, sodass wir die Module in unserem Code verwenden können.
Als nächstes müssen wir die Iris Daten laden. Erstellt dafür eine neue Code-Zelle mit diesem Inhalt und führt sie aus:
df = pd.read_csv('./data/iris_data.csv')
df.head()
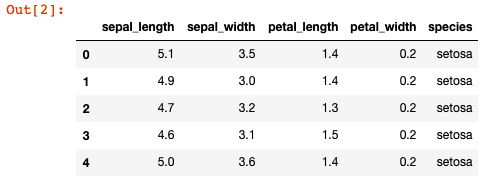
Mit diesem Code laden wir die Daten aus der CSV-Datei. Die Funktion pd.read_csv() liefert uns einen DataFrame, welchen wir in der Variable df speichern.
Die Methode head() vom df Objekt zeigt uns alle Features (Spalten) und die ersten Fälle (Zeilen) in den geladenen Daten.
Übrigens: Funktionen innerhalb von Objekten (bzw. Klassen) nennt man Methoden. read_csv() ist eine Funktion aus dem Pandas Modul und head() eine Methode eines DataFrame-Objekts.
Wir möchten mehr über unsere Daten erfahren. Dafür lassen wir uns die Form des DataFrames ausgeben:
df.shape
Output: (150, 5)
Das bedeutet unser Datensatz enthält 150 Fälle (Zeilen) und 5 Features (Spalten).
Mit einer Visualisierung möchten wir weitere Erkenntnisse über die Daten gewinnen. Gebt folgendes in die nächste Code-Zelle und führt sie aus:
colors = {'setosa' : 'r', 'versicolor' : 'g', 'virginica' : 'b'}
fig, ax = plt.subplots(figsize=(10, 5))
for i in range(len(df['sepal_length'])):
ax.scatter(df['sepal_length'][i], df['sepal_width'][i],color=colors[df['species'][i]])
ax.set_title('Iris Daten')
ax.set_xlabel('Sepal length')
ax.set_ylabel('Sepal width')
Matplotlib Code ist nicht unbedingt intuitiv zu verstehen für Anfänger. In diesem Tutorial soll Matplotlib Pyplot aber nicht näher behandelt werden.
Wir erhalten ein Scatterplot für die Features Sepal length und Sepal width. Außerdem lässt sich die Klassenzugehörigkeit der Datenpunkte anhand der Farbe (rot: Iris-Setosa, grün: Iris-versicolor, blau: Iris-virginica) ablesen.
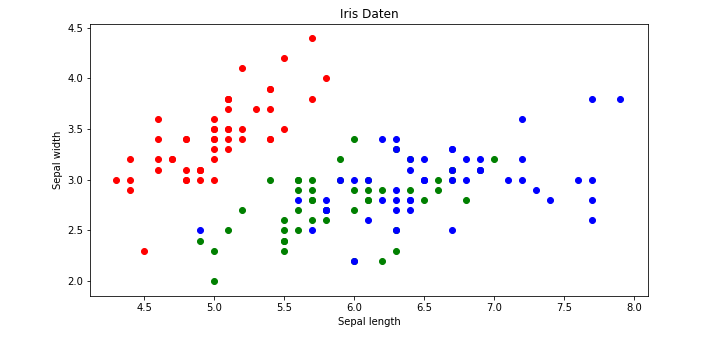
Aus dem Schaubild geht hervor, dass man die 3 Klassen nicht gut mit einem Linearen Klassifizierer nur anhand der 2 Features (Sepal length und Sepal width) auseinanderhalten kann. Denkt man sich eine Linie als Modell, so würde diese zwar die roten und blauen Datenpunkte gut separieren aber nicht die grünen Punkte.
Allerdings haben wir mehr als 2 Features in den Daten (nämlich noch Petal length und Petal width), welche wir auch für unser Modell verwenden sollten. Mehr als 2 bzw. 3 Dimensionen lassen sich jedoch schlecht grafisch darstellen.
Achtung: Es handelt sich bei den Iris-Daten um ein Klassifikationsproblem. Also können wir nicht wie oben eine Lineare Regression anwenden. Stattdessen werden wir eine Logistische Regression anwenden.
Vorverarbeitung der Daten für Machine Learning
Wir möchten nun verschiedene Supervised Machine Learning Algorithmen auf die Daten anwenden.
Die meisten ML Learning Algorithmen können nur mit Zahlen umgehen.
In unseren Daten in der Spalte ‘species’ haben wir jedoch die Klassen als Strings (Zeichenketten) vorliegen. Also müssen wir diese in Zahlen (Integer) umwandeln. Es gibt verschiedene Möglichkeiten nicht-numerische in numerische Features mit Python umzuwandeln.
Wir halten es einfach in diesem Tutorial:
species_to_int = {'setosa': 0, 'versicolor': 1, 'virginica': 2}
df['species'] = df['species'].map(species_to_int)
df.head()
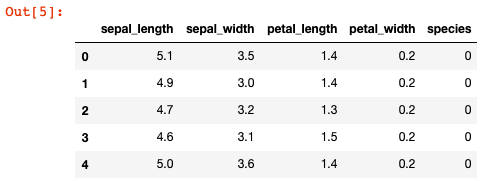
Im species_to_int Dictionary mappen wir die Spezies zu Zahlen.
Dieses Dictionary geben wir df[‘species’].map() als Input und überschreiben die alten (nicht-numerischen) Werte mit den neuen numerischen Werten. Mit df.head() sehen wir das Ergebnis.
Erinnern wir uns für den nächsten Vorverarbeitungs-Schritt an das Beispiel mit der Linearen Regression weiter oben:
Auch beim Iris-Problem haben wir eine abhängige Variable “y” (Species) und mehrere unabhängige Variablen “X” (Sepal length, Sepal width, Petal length und Petal width).
Wir müssen also X und y aus unserem gesamten Datensatz gewinnen. Pandas eignet sich hervorragend für diese Aufgabe:
X = df.iloc[:,:-1]
y = df.iloc[:,-1]
print('X:', X.shape,' y:', y.shape)
Output: X: (150, 4) y: (150,)
Mit df.iloc[] lassen sich bestimmte Daten aus einem DataFrame auswählen.
Wir weisen den Rückgabewert von df.iloc[:, :-1] unserem X zu. Dabei haben wir aus unserem DataFrame alle Zeilen (erster “:” in den eckigen Klammern) und alle Spalten bis auf die letzte (“:-1” in den eckigen Klammern) ausgewählt.
Den Rückgabewert von df.iloc[:, -1] weisen wir unserem y zu. Dabei erhalten wir alle Zeilen und nur die letzte Spalte aus unserem DataFrame.
X besteht aus 150 Zeilen und 4 Spalten, wie sich aus X.shape (150, 4) ablesen lässt. Dabei handelt es sich um unsere Featurematrix.
y besteht ebenfalls aus 150 Zeilen aber nur einer einzigen Spalte, wie sich aus y.shape (150, ) ablesen lässt. Dabei handelt es sich um unseren Zielvektor.

Ein weiterer wichtiger Schritt fehlt noch, bevor wir verschiedene ML Algorithmen auf die Daten anwenden können.
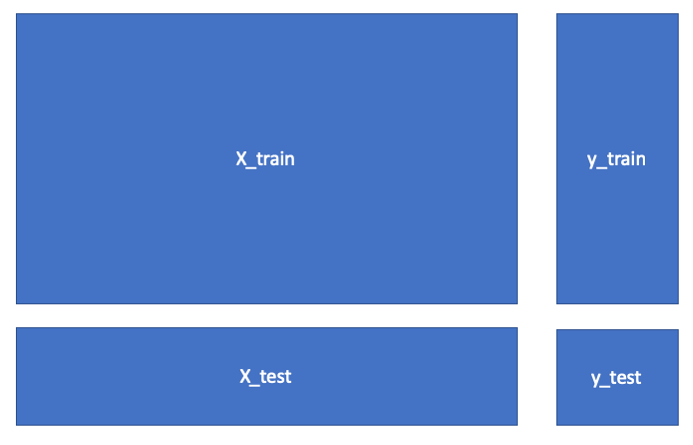
Wir müssen unsere Daten in Trainings- und Testdaten aufteilen.
Die Trainingsdaten geben wir den ML Algorithmen als Input, sodass diese damit Modelle trainieren bzw. “lernen” können.
Mit den Testdaten können wir dann die Performance unserer Modelle bewerten.
Wieso trainiert man die Modelle nicht einfach mit allen Daten?
Dadurch möchte man vermeiden, dass in den Modellen die Daten vereinfacht gesagt “auswendig” gelernt werden. Dieses Phänomen wird als Overfitting bezeichnet und es führt dazu, dass Modelle nicht gut auf neue unbekannte Fälle anwendbar sind.
Scikit-learn enthält eine nützliche Funktion zum Aufteilen von Daten in Trainings- und Testdaten:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print('X_train:', X_train.shape, ' y_train:', y_train.shape)
print('X_test:', X_test.shape, ' y_test:', y_test.shape)
Output: X_train: (120, 4) y_train: (120,)
X_test: (30, 4) y_test: (30,)
Zunächst importieren wir die train_test_split() Funktion von Scikit-learn.
Danach weisen wir 4 Variablen (X_train, X_test, y_train, y_test) über Multiple Assignment mit dem Aufruf von train_test_split(X, y, test_size=0.2, random_state=42) die entsprechenden Werte zu.
Die Inputparameter der Funktion train_test_split() lauten:
- X: Featurematrix aller Daten
- y: Zielvektor (Labels)
- test_size: Prozentuale Größe des neuen Test-Datensatzes (X_test)
- random_state: Zufallsparameter zur Reproduktion der Ergebnisse
Der Output lautet:
- X_train: Trainingsdaten (Features)
- y_train: Zielvektor (Labels) der Trainingsdaten
- X_test: Testdaten (Features)
- y_test: Zielvektor (Labels) der Testdaten
Wir haben uns auch die Form (Zeilen, Spalten) der Trainings- und Testdaten ausgegeben lassen.
Hier ist das ganze nochmal anschaulich:
Initiierung, Training und Evaluation von Machine Learning Modellen
Nach der ganzen Vorarbeit können wir nun verschiedene Machine Learning Modelle initiieren, trainieren, anwenden und bewerten.
Mit Scikit-learn sind diese Schritte sehr einfach durchzuführen! 🙂
Zunächst initiieren und trainieren wir ein Modell mit einer Logistischen Regression:
from sklearn.linear_model import LogisticRegression
log_clf = LogisticRegression()
log_clf.fit(X_train, y_train)

Hinweis: Möglicherweise bekommt ihr bei diesem Code auch eine “FutureWarning” angezeigt. Ignoriert diese einfach.
Machine Learning Modelle sind in Scikit-learn als Python Klassen implementiert.
Zuerst importieren wir den Logistischen Regressions Klassifizierer aus Scikit-learn.
Danach instanziieren wir die Klasse und speichern das resultierende Objekt als log_clf.
Jede in Scikit-learn implementierte ML Methode kann mit vielen Hyperparametern modifiziert werden, welche bei der Instanziierung angegeben werden. Gibt man keine Hyperparameter an, so werden die Default-Werte für die Parameter gewählt.
Anschließend trainieren wir das Modell mit der log_clf.fit(X_train, y_train) Methode auf den Trainingsdaten.
Als Output erhalten wir unser Modell mit den (Standard) Hyperparametern.
Im Folgenden werden wir unser gelerntes Modell anwenden und anhand einer geeigneten Performance-Metrik evaluieren:
from sklearn.metrics import accuracy_score
y_pred = log_clf.predict(X_test)
acc_score = accuracy_score(y_test, y_pred)
print('Accuracy:', acc_score)
Output: Accuracy: 1.0
Eine geeignete Performance-Metrik ist die Accuracy. Sie beschreibt den Anteil der richtigen Vorhersagen an allen (richtigen und falschen) Vorhersagen.
Wir importieren die Funktion accuracy_score aus Scikit-learn zur Berechnung der Accuracy.
Mit log_clf.predict(X_test) wenden wir unser Modell an und generieren Vorhersagen für alle Fälle im Testdatensatz. Die Ergebnisse (Numpy Array) speichern wir als y_pred.
Mit accuracy_score(y_test, y_pred) berechnen wir schließlich die Accuracy und speichern den Wert in der Variable acc_score. Dabei werden die tatsächlichen Ergebnisse (y_test) also die “Ground Truth” mit den vorhergesagten Werten verglichen.
In unserem Fall stimmen y_pred und y_test komplett überein, sodass die Accuracy 1.0 beträgt. Unser Modell kann also alle Fälle im Testdatensatz richtig klassifizieren!
Andere Machine Learning Modelle
Es ist nun auch ganz einfach möglich andere ML Modelle aus Scikit-learn auf die Daten anzuwenden und zu bewerten.
Lasst uns zum Abschluss noch einen Entscheidungsbaum (Decision Tree) auf die Daten anwenden:
from sklearn.tree import DecisionTreeClassifier
tree_clf = DecisionTreeClassifier()
tree_clf.fit(X_train, y_train)
print('Accuracy Decision Tree:', tree_clf.score(X_test, y_test))
Output: Accuracy Decision Tree: 1.0
Der Prozess ist gleich wie oben:
Zunächst müssen wir den Entscheidungsbaum Klassifizierer aus Scikit-learn importieren.
Anschließend erstellen wir ein Klassifizierer-Objekt aus der importierten Klasse. Dieses trainieren wir auf den Trainingsdaten.
Danach lassen wir uns die Accuracy ausgeben (diesmal auf eine andere Weise wie oben).
Auch mit einem Entscheidungsbaum werden die Testdaten alle richtig vorhergesagt, sodass die Accuracy 1.0 beträgt!
Die Standardwerte der Hyperparameter sind offensichtlich auch hier gut gewählt. Wir können absichtlich weniger sinnvolle Werte auswählen, um zu sehen wie das Modell schlechter abschneidet:
from sklearn.tree import DecisionTreeClassifier
tree_clf = DecisionTreeClassifier(max_depth=1)
tree_clf.fit(X_train, y_train)
print('Accuracy Bad Decision Tree:', tree_clf.score(X_test, y_test))
Output: Accuracy Bad Decision Tree: 0.6333333333333333
Hier instanziieren wir einen Entscheidungsbaum mit dem Hyperparameter max_depth=1. Das bedeutet der Entscheidungsbaum darf nur eine maximale Tiefe von 1 haben.
Das ist offensichtlich nicht hilfreich für unsere Vorhersagen, sodass sich die Accuracy auf 63,33 % verringert.
Scikit-learn stellt eine Vielzahl an Machine Learning Verfahren wie z. B. Support Vector Machines oder Künstliche Neuronale Netze zur Verfügung, die ihr zusätzlich ausprobieren könnt.
Fazit und weitere Anmerkungen
Damit neigt sich dieses umfangreiche Tutorial über Machine Learning mit Python dem Ende zu.
Lasst uns die behandelten Themen noch mal kurz zusammenfassen:
- Python ist eine weit verbreitete Programmiersprache (Technologie) und bietet hervorragende Unterstützung für Machine Learning.
- Machine Learning erlaubt es mit den richtigen Daten und lernenden Algorithmen nützliche Modelle für Problemstellungen zu entwickeln.
- Machine Learning in Python erfordert grundlegende Kenntnisse in Python, eine Entwicklungsumgebung sowie etwas Kenntnis in Statistik und Mathematik.
- Dank freien Packages wie Scikit-learn, Pandas und Numpy lässt sich Machine Learning in Python praktisch und ohne viel Aufwand anwenden.
Mit diesem Beitrag wollte ich eine umfassende, verständliche und praktische Einführung in Machine Learning mit Python liefern. Außerdem wollte ich auch einen konzeptionellen Rahmen für das Thema geben und nicht nur Code zeigen. Es ging darum, an einem idealisierten Beispiel grundlegende Machine Learning Konzepte (mit Python) aufzuzeigen. Viele reale Herausforderungen bei Machine Learning wurden nicht oder nur oberflächlich benannt. Aber man kann und sollte ja nicht alles in einen Beitrag packen! 🙂
Schreibt eure Fragen, Anmerkungen und Feedback gerne in die Kommentare!
Referenzen
-
- Domingos, Pedro: The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World
- VanderPlas, Jake: Python Data Science Handbook: Essential Tools for working with Data
- Géron, Aurélien: Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques for Building Intelligent Systems

Der Autor hat Wirtschaftsinformatik (M. Sc.) am Karlsruher Institut für Technologie (KIT) studiert. Dabei hat er sich auf Machine Learning, Data Science und das Web spezialisiert. Den Bachelor hat er in BWL mit Schwerpunkt Wirtschaftspsychologie absolviert. Daneben treibt er in seiner Freizeit gerne Sport oder geht auf Reisen.
17 Kommentare. Hinterlasse eine Antwort
Danke für das tolle Tutorial – das hilft mir weiter!
Interessanter und ausführlicher Beitrag!
Wirklich sehr anschaulich erklärt! Vielen Dank
Vielen Dank für dieses ausführliche und hilfreiche Tutorial! Es hat inhaltlich alles super abgedeckt, sodass ich mich als komplette Anfängerin tatsächlich ans programmieren traue. 🙂
Hallo Lisa,
Danke das freut mich zu hören! 🙂
Interessantes Tutorial!! Habe mich vor kurzem als totaler Anfänger an Python gewagt und deinen Beitrag entdeckt! Vielen Dank!!
Hallo Kati,
schön, dass dir das Tutorial gefällt. Und viel Erfolg mit Python!
Ein super Tutorial. Hat mir sehr geholfen!!
Sehr ausführliches Tutorial. Danke !
Das Tutorial hat mir wirklich weitergeholfen. Danke dafür !
Tolles Tutorial, hat mir wirklich weitergeholfen , vielen Dank !
Das Tutorial von gwebservice deckt alle relevanten Bereiche für einen Einstieg in Machine Learning ab. Dank der ausführlichen und praxisnahen Erklärung auch für Fachfremde geeignet- Danke gwebservice!
Danke!
Gutes Tutorial!
Der Verweis auf Anaconda zur Einrichtung der Entwiklungsumgebung hat mir sehr geholfen.
Sehr hilfreich!
Dankeschön 🙂
Vielen Dank!